Falls Church History Room Index & IIIFScribe
Next.js
Supabase
OpenAI
Tesseract.js
IIIF
Tailwind CSS
When I discovered that the Mary Riley Styles Public Library kept its five local-history indexes online only as scanned images, I knew there had to be a better way to search them.
The Problem
Hundreds of pages of priceless Falls Church history were locked inside images — no text search, no filtering, and no easy way for historians (or curious locals like me) to explore the collection.
My Solution
- IIIFScribe — a custom OCR pipeline that:
- Accepts any IIIF manifest
- Downloads each high-resolution page
- Extracts text with Tesseract.js
- Generates a markdown transcript with full front-matter and page markers
- Data Pipeline
- Converts the transcript to JSON
- Loads it into a Supabase Postgres table
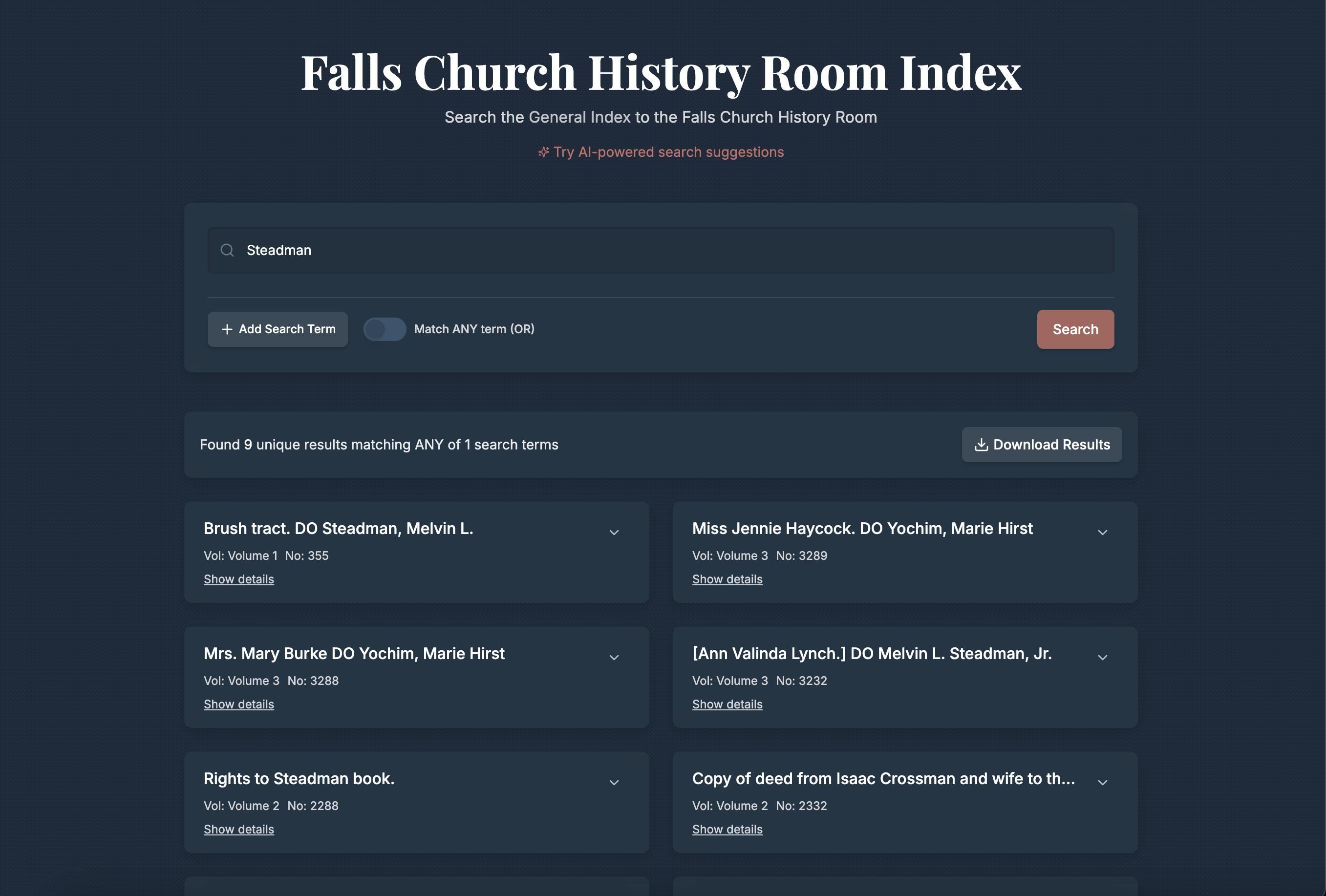
- Search Interface
- Built with Next.js 14 App Router + shadcn/ui
- Boolean (AND/OR) multi-term search across title, subject, notes, and more
- Downloads results as JSON
- AI-Powered Suggestions
- An OpenAI-backed endpoint that turns a research prompt into optimized search terms tailored to the Falls Church corpus.
What I Like
- First time wrangling IIIF manifests at scale — now it feels easy.
- Watching the OCR progress bar chew through 700+ pages in real time.
- The AI suggestion panel routinely surfaces terms I never would have thought of.
Screenshots
1 / 3